Adressage du réseau logique
Principe de l'adressage IP
Chaque machine (host), raccordée au réseau logique IP, est identifiée par un identifiant logique ou adresse IP (@IP) indépendant de l'adressage physique utilisée dans le réseau réél. Le réseau logique IP masquant le réseau physique, pour assurer l'acheminement des données, il est nécessaire de définir des mécanismes de mise en relation de l'adresse logique, seule connue des applications, avec l'adresse physique correspondante.
Cette adresse est unique pour chaque hôte qui communique via TCP/IP. Chaque adresse IP est codé sur 32 bits ; cela identifie un emplacement d'un système hôte sur le réseau de la même façon qu'une adresse de rue identifie une maison dans une ville.
Une adresse de rue a un format standard en deux parties "un nom de rue et un numéro de maison", une adresse IP est basée sur le même système de deux parties : un ID de réseau (Net_ID) et un ID d'hôte (Host_ID) : L'ID de réseau, également appelé adresse de réseau, identifie un segment de réseau unique dans un réseau d'interconnexion TCP/IP plus grand. Tous les systèmes associés au même réseau et partageant l'accès à ce réseau ont un ID de réseau commun dans leur adresse IP complète. Cet ID est également utilisé pour identifier de manière unique chaque réseau dans le réseau d'interconnexion le plus grand.
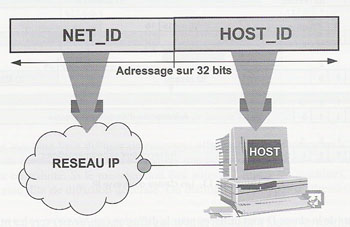
Figure 1 L'adressage dans le réseau logique IP
Les techniques d'adressage dans le réseau IP
Les classes d'adressage
Les adresses IP sont limitées à 4 octets (32 bits), on represente l'adresse IP par 4 valeurs décimales séparées par un point (cette notation s'appelle la notation décimale pointée). Afin d'assurer une meilleure utilisation de l'espace d'adressage et d'apapter celui-ci à la taille et au besoin de chaque organisation, il a été introduit une modularité dans la répartition des octets entre l'identifiant réseau et l'identifiant machine. Ainsi les 5 classes d'adresses sont nées. Les premiers bits du champ adresse réseau (Net_ID) permettent de distinguer la classe d'adressage.
Les adresses de classe A s'étendent de 1.0.0.1 à 126.255.255.254. Elles permettent d'adresser 126 réseaux (2^7 - 2) et plus de 16 millions de machines (2^24 - 2 soit 16777214).
Les adresses de classse B vont de 128.0.0.1 à 191.255.255.254, ce qui correspond à plus de 16384 réseaux de 65533 machines. Cette classe est la plus utilisée et les adresses sont pratiquement aujourd'hui épuisées.
Les adresses de classe C couvre les adresses 192.0.0.1 à 223.255.255.254, elle adresse plus de 2 millions de réseaux (2097152) de 254 machines.

Figure 2 Les classes d'adresse IP
Les adresses de classe D sont utilisées pour la diffusion (multicast) vers les machines d'un même groupe. Elles vont de 224.0.0.0 à 239.255.255.254. Ce groupe peut être un ensemble de machines mais aussi un ensemble de routeurs (diffusion de tables de routage). Tous les systèmes ne supportent pas les adresses de multicast. Enfin les adresses de la classe E sont réservées aux expérimentations.
Les adresses spéciales
Tout host d'un réseau IP est identifié par le couple <Net_ID><Host_ID>. Certaines valeurs de ces champs ont une signification particulière. C'est ainsi que l'adresse <Net_ID><0>, où tous les bits du champ Host_ID à zéro, désigne le réseau lui-même (par exemple : 10.0.0.0 => le réseau 10).
La machines elle-même ou machine locale peut être auto-adressée avec une adresse de la forme 127.x.x.X, cette adresse dite de boucle locale (loopback ou encore localhost) est utilisée lors de tests de la machine ou de programmes applicatifs. Tout datagramme émis à destination d'une adresse 127.x.x.x est directement recopié du tampon d'émission vers le tampon de réception, il n'est jamais émis dur le réseau, ce qui protège ce dernier d'éventuels dysfonctionnements du nouvel applicatif.

Figure 3 L'adresse de boucle locale.
Lorsqu'une machine veut diffuser un message, elle peut, si le message ne s'adresse qu'à un ensemble de machines particulières, utiliser une adresse de multicast dite aussi de diffusion restreinte ou réduite. Si le message doit être adressé à toutes les machines, elles utilisera alors une adresse dite de diffusion générale. On distingue deux types d'adresses de diffusion générale :
- L'adresse 255.255.255.255 utilisée pour envoyer un message à toutes les machines du même segment de réseau. La diffusion est limitée aux seules machines de ce segment, le datagramme n'est pas frelayé sur d'autres réseaux. L'adresse 255.255.255.255 est dite adresse diffusion générale ou limitée.
- Si une machine veut s'adresser à toutes les machines d'un autre réseau, elle utilisera une adresse du type <Net_ID><1>, tous les bits à 1 du champ Host_ID identifient toutes les machines du réseau <Net_ID><0>. Ce message de diffusion est relayé de réseau en réseau pour atteindre le réseau destinataire. L'adresse est dite de diffusion dirigée.

Figure 4 Les types de diffusion
Ainsi :
- L'adresse 123.0.0.0 désigne le réseau 123 ;
- L'adresse 123.0.0.7 désigne la machine 7 du réseau 123 ;
- L'adresse 123.255.255.255 est l'adresse de diffusion dirigée à utiliser pour envoyer un message à toutes les machines du réseau 123 ;
- L'adresse 255.255.255.255 est l'adresse de diffusion des machines du même segmant de réseau que la machine source.
Adresses publiques et adresses privées
Afin de permettre l'interconnexion des réseaux, il faut garantir l'unicité des adresses. C'est pour cela que l'IANA attribue à chaque réseau un identifiant unique. Hors tous les réseaux n'ont pas nécessairement un besoin d'interconnexion via un réseau public dans ce cas l'unicité d'adresse au plan mondial est inutile. Certaines entreprises ou particuliers disposent de leur propre réseau (réseau privé) et n'ont aucun besoin d'interconnexion vers l'extérieur, il est alors possible d'utiliser n'importe quelle adresse IP. Ces adresses-là soit dite illégales en opposition à celle de l'IANA qui sont elles légales :).
Afin d'éviter une anarchie dans l'utilisation des adresses, il a été réserver des plages d'adresse à ces réseaux. Ces adresses ne sont pas routables sur le réseau internet. Elles sont exclusivement réservées à un usage privé. Celles-ci sont dite adresses privé tandis que les autres sont dites adresses publiques.
| Classe | Début de la plage | Fin de la plage | Nombre de réseaux |
|---|---|---|---|
| A | 10.0.0.0 |
1 |
|
| B | 172.16.0.0 |
172.31.0.0 |
16 |
| C | 192.168.0.0 |
192.168.255.0 |
256 |
Figure 5 Les adresses privées
Si on posséde un réseau utilisant des adresses de types privé et que l'on a soudainement des besoins d'avoir accès à un réseau public, il existe deux solutions :
- Renuméroter toutes les stations avec des adresses publiques
- Ou réaliser une conversion d'adresses (NAT, Network Address Translator), c'est-à-dire mettre en correspondance une adresse privée avec une adresse publique.
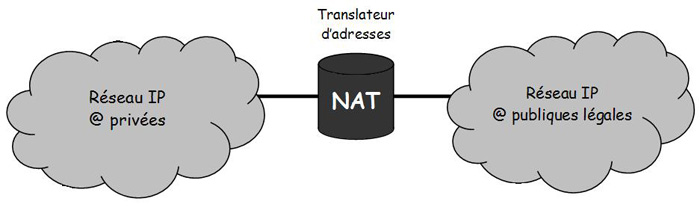
Figure 6 Le NAT est l'interface entre un réseau privé et un réseau public
La seconde solution est généralement adoptée. La passerelle d'accès au réseau public réalisera la translation d'adresses (voir figure 6). La traduction peut être statique, dans ce cas la table de correspondance sera renseignée par l'administrateur du réseau, ou dynamique quand la mise en correspondance adresse privée/publique est definie au moment du besoin d'interconnexion. Les adresses publiques peuvent alors être partagées par l'ensemble des machines du réseau privé. Cette traduction dynamique permet de n'utiliser qu'un nombre restreint d'adresses publiques.
Notions de sous-réseau : le subnetting
- Nécessité de définir des sous-réseaux
Imaginons qu'une entreprise est réparties son parc informatique sur deux sites, A et B (voir figure 7). Les tables de résolution d'adresses des passerelles d'accès au réseau physique doivent contenir une entrée par machine du site, alors que l'adresse physique est la même. Afin d'alléger cette table et aussi de faciliter le routage, on pourrait de doter chaque réseau de site (sous-réseau) d'un identifiant réseau <Net_ID>. Cette approche est consommatrice d'adresses IP. Il est donc préférable de n'attribuer qu'un seul identifiant de réseau (c'est-à-dire 1 seul réseau logique IP par entreprise) et de remplacer l'énumération d'adresses IP par un identifiant de site.
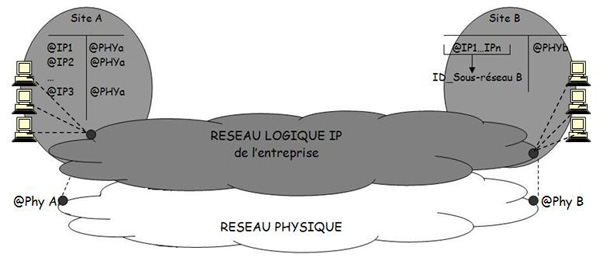
Figure 7 Notion de sous-réseaux logiques.
En pratiquant de la sorte, tout le noeud du réseau logique est parfaitement différencié et localisé par un unique identifiant du réseau logique <Net_ID> et un identifiant du site local ou sous-réseau appelé <SubNet_ID> et le numéro de la machine ou host (voir figure 8). A l'origine, l'adressage IP ne prend pas en compte ce type de structure d'adresse. En pratique, tous les bits du champ <Host_ID> ne sont pas tous utilisés pour numéroter les machines, il suffit donc d'en prélever quelques-uns pour identifier un sous-réseau. La taille de ce dernier (<SubNet_ID>) sera déterminée en fonction du nombre de sous-réseaux à distinguer.
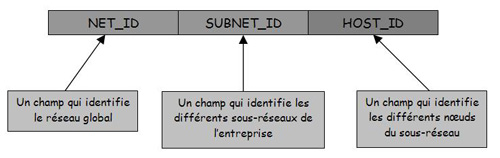
Figure 8 Le sous-réseau décompose l'adresse IP en 3 champs.
En réalité, l'acheminement est réalisé à partir du champ <Net_ID> dont la taille, dependant de la classe d'adresse, est connue de chaque routeur. L'utilisation d'un identifiant supplémentaire de longueur variable nécessite d'indiquer à chaque host du réseau quels sont les bits de l'adresse IP à prendre en compte pour définir l'acheminement dans le réseau. Cette information est fournie sous forme d'un champ de bits à 1 appelé masque de sous-réseau.
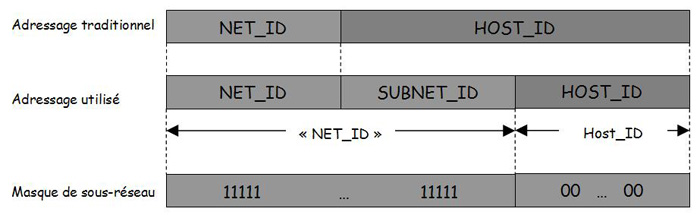
Figure 9 Principe du masque de sous-réseau
Il existe deux méthodes d'écriture des masques de sous-réseaux, qui sont équivalentes :
- Réseau : 10.0.0.0, masque de sous-réseau 255.255.240.0 ;
- Ou plus simplement 10.0.0.0/20, le prééfixe 20 indique la longueur en bits du masque de sous-réseau (longueur du préfixe ou simplement préfixe).
- Utilisation du masque de sous-réseau
Lorsqu'une statio émet une trame à destinatio d'une autre station, la couche IP locale vérifie, à l'aide du masque de sous-réseau, si la trame appartient au même sous-réseau que celui de l'émetteur. Si la trame est destinée à une station située sur un sous-réseau distant, la trame est alors envoyé à la passerelle par défaut, charge celle-ci d'adresser la trame vers le bon sous-réseau. Ainsi, lorsque l'on configure sa carte réseau, il faut connaitre :
- son adresse IP
- la masque de sous-réseau
- l'adresse de la passerelle locale (routeur)

Figure 10 Propriètés d'une carte réseau sous windows XP
Pour déterminer, si une machine cible est localisé sur le même sous-réseau, la machine source réalise un "ET logique" entre les bits de l'adresse source et ceux du masque de sous-réseau, elle procède de même avec l'adresse destination.
E1 |
E2 |
S |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
1 |
1 |
Figure 11 Table de vérité d'un ET logique
Si le résultat donne une valeur identique alors les deux machines sont sur le même sous-réseau, sinon la trame est adressé au routeur.

Figure 12 Détermination du sous-réseau cible à l'aide du masque de sous-réseau.
- Broadcast de sous-réseau
Deux types de broadcast (diffusion) ont été définis, pour prendre en compte les sous-réseaux, il en convient d'en ajouter un troisième :
- 255.255.255.255, adresse toutes les machines du réseau sur lequel il a été émis. Ce broadcast ne franchit pas les passerelles, broadcast limité.
- <Net_ID>.<1>, tous les bits du champ <Host_ID> à 1, désigne toutes les machines du réseau <Net_ID>. Ce broadcast, dit broadcast dirigé, est acheminé par les passerelles, sauf configuration spécifique de celles-ci.
- <Net_ID>.<SubNet_ID>.<1>, tous les bits du champ <Host_ID> à 1 adresse toutes les machines du sous-réseau <SubNet_ID>.